Column oriented database or Row oriented database

samundrak
JavaScript DevDatabase types and storing way don't matter much when we don’t have a big amount of data but as our data grows, we start facing issues. Many of us will start fixing by reducing multiple joins where it is not required. Also, start denormalizing as we normalized it soo much that we now have to join 5+ tables to get just some counts. This thing does matter but sometimes we also have to think about how we are storing our data and what type of storage engine we are using to fetch records faster.
Example of column oriented and row oriented database
As per Wikipedia Column-oriented storage is a database management system that stores data by column rather than a row. Further simplifying this we can understand that in a row-oriented storage data is accessed on a row basis and while fetching the data by row it will go to every row and, fetch all columns and return only the column asked in the select query but in column-oriented storage, data is fetched only from the column that is asked and will ignore nonrelated columns.
Suppose we have a table where we are storing employee’s records and it can look like any other table with rows and columns.
In analytical reporting which makes maximum use of aggregate functions normally ends up collecting records from multiple tables. Joining multiple tables on every request can be expensive and normally they are mitigated by doing denormalization attempts like creating a view or materialized view. If we have trillion of rows and data in our tables, storing and querying them efficiently will be a challenging problem. A typical warehouse query only has to access 4 or 5 columns but it can have 100 columns. It will go through a large number of rows but only 2 or 3 columns are needed and the query will ignore all other columns.
Most OLTP(Online Transaction Processing) databases are structured in a row-oriented fashion and all the values on one row are store next to each other. We may have indexes on some columns but still, the database has to load all of those rows and each can have 50+ columns from the hard disk to memory, parse them and filter the data that doesn’t meet the requirements like excluding the columns that are not needed.
Column-oriented storage pushes the concept of not storing data based on the row but to store all the values from each column together and if the column is stored in a separate file then only that file will be opened, parsed, and executed which will save a lot of time.
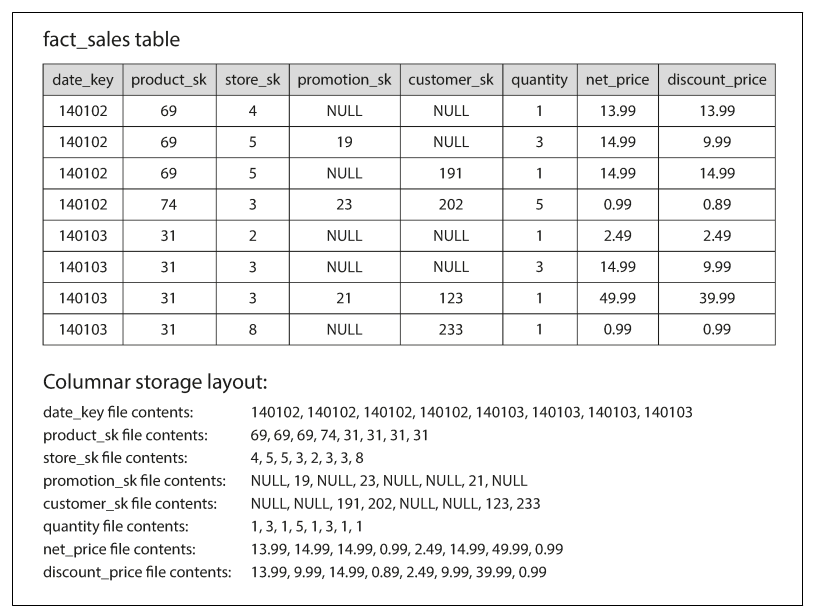
Assuming we have table fact_sales which has records of all the sales and if we want to illustrate it into row-oriented and column-oriented storage then the Figure provided below can make our concept clear about how it is structured.
Column Compression
Not only loading columns from disk are required for the query we can also further reduce the demands on disk throughput by compressing data and column-oriented storage comes with this service. If we look at the sequence of value in each column then we can see most of them repetitive which is good for compression and depend on the data different compression techniques can apply and among them, bitmap encoding is effective in the data warehouse.
Further Reading
- Designing Data Intensive Application